
킹의 개발일지
해시(Hash) 본문
해시
해시는 '해시함수(hash function) h를 사용해서 특정 키 k를 테이블에 넣을 때 사용할 인덱스로 변환하는것' 이라고 할 수 있다. 이를 index = h(k) 처럼 나타 낼 수 있으며, 테이블을 T라고 한다면, 키에 대응되는 값 x를 T[h(k)] = x 형식으로 저장 할 수 있다.
보통, 키 k의 갯수는 테이블의 크기 m보다 큰데, 이 때문에 키는 다르지만 해시함수에 의해서 반환되는 값이 같을 때가 생길 수 있다. 이 경우를 '충돌'이 일어났다고 한다.
백문이 불여일견이라고 간단한 해시함수를 보면서 이해해보도록 하자.
해시함수 h를 다음과 같이 정의해보자. 여기서 x는 키를 의미하고 m은 배열의 크기를 의미한다.
h(x) = x%m
즉, 해시값은 키를 배열의 크기로 나눈 나머지가 된다. 이 때 반환되는 값들은 0~ m-1까지이다. 이 때 배열의 크기 m을 100이라고 하고 키가 1024와 2024가 있다고 해보자. 키 1024와 2024의 해시값은 24로 동일하다. 그렇기 때문에 테이블의 같은 공간에 값이 저장될 것이다. 슬롯 하나당 여러 값이 들어갈 수 있다면 문제가 없겠지만 보통 그럴 순 없기에 문제가 된다.
해시 함수가 충돌이 생기지 않게 해시값을 만들어 낸다면 문제가 없겠지만, 보통 입력값의 범위가 출력값의 범위보다 크기에 충돌 자체를 막을 수 없을것이다.
또한 충돌을 없애기 위해서 해시값 집합보다 m의 크기를 크게 해주면서, 해시값이 중복되지 않도록 해시함수를 만들면 되겠지만 테이블의 크기를 무한정 크게 만들 순 없기에 우리는 충돌을 해결하는 방법을 찾아야한다. 이는 뒤에서 알아보도록 하자.
삽입, 삭제, 탐색
해시 자료구조의 경우, 충돌이 없다고 생각하면, 탐색, 삽입, 삭제에 걸리는 시간이 O(1)이 될 것이다. 찾고자하는 값의 키를 해시 함수에 넣어, T[h(k)]로 값을 찾을수 있으며, 삽입과 삭제 또한 같은 방식으로 실행하면 된다.
충돌 대처 방법들
충돌이 발생했을 때 대처할 수 있는 방법으로 크게 Chaining과 Open Addressing이 있다. 먼저 Chaining을 보도록 하자.
Chaining
위에서 key에 해당하는 슬롯에 값이 하나만 들어간다면 문제가 된다고 했는데, Chaining은 충돌이 발생했을 때 key에 해당하는 슬롯에 여러 값들을 저장할 수 있게 해줌으로써 충돌을 해결한다.
여러 값들을 저장하는 방법으로 연결리스트를 사용한다.

위 그림을 보면 k5, k7, k2들은 같은 해시값을 갖는다. 때문에 같은 슬롯에 값들이 저장되는데, 해당 슬롯에는 각 해시값을 연결리스트로 붙혀놨다.
1. Chaining에서 삽입 연산은 충돌이 일어났을 때, 간단히 연결리스트의 맨 앞부분에 데이터를 연결하면 됨으로, O(1)의 시간이 걸린다. 허나 중복을 허용하지 않는다면, 해시값 리스트를 탐색해야함으로 O(k) 시간이 걸릴 수 있다. 이 때 k는 해시값들의 갯수다.
2. Chaining에서 검색 연산은 충돌이 발생했을시, 연결리스트를 탐색해야 하므로 연산 시간은 리스트 길이에 비례할 것이다.
3. 삭제 연산은 먼저 검색으로 해당 값을 찾아야함으로 리스트에 비례하는 시간이 걸릴테지만 삭제 자체는 O(1)이 걸린다.
Chaining에서 최악의 경우는 모든 해시값이 하나의 슬롯에 할당되는 경우인데, 탐색, 삽입, 삭제 모두 연결리스트 길이에 비례하는 시간이 걸릴 것이다. 그렇기 때문에 해시에서는 각 키의 해시 값이 최대한 균등하게 퍼져야 성능이 좋아지고, 그러기 위해서는 주어진 데이터에 대한 좋은 해시 함수를 정해야한다.
Open Addressing
Open Addressing 기법은 체이닝 기법과는 다르게, 한 슬롯에는 하나의 값만이 들어간다. 따라서 충돌이 생기면 다른 키들은 다른 슬롯에 저장되어야한다.
Open Addressing 기법에도 여러 방법들이 존재하는데, 가장 기본적인 방법인 Linear probing 방법을 살펴보자.
Linear probing
Linear probing은 다른 기법들과 동일하게, 해시값에 해당되는 슬롯이 비어있다면 바로 할당한다. 만약 충돌이 발생하면 다른 슬롯을 탐색하고 빈슬롯이 있다면 값을 저장한다. 계속 탐색하다가 테이블의 끝을 만날경우, 0번 슬롯으로 Circular하게 넘어가면 된다.
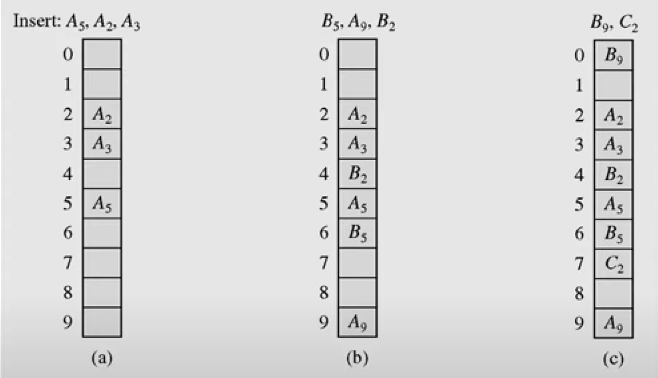
위 예시를 보면 처음 삽입시, 원소 A5, A2, A3 (각 아래 첨자는 해시값을 의미한다.) 는 해시에 해당하는 슬롯이 비어있기에 바로 할당할 수 있다. 하지만 두번째 삽입부터 충돌이 생긴다. B5는 5번째 슬롯에 들어가야 하지만, A5가 이미 차지하고 있기 때문에 바로 아래 슬롯인, 6번째 배열에 값을 넣는다. 마찬가지로 B2도 두번째 슬롯이 아니라 세번째 슬롯에 값이 들어가게 된다. (c)의 경우도 동일하게 진행하면 된다. 참고로 A9의 경우 배열의 끝임으로 B9는 0번 슬롯에 값이 들어간다.
충돌이 발생한 키에 해당하는 값을 찾기 위해서는 원래 키에 해당하는 슬롯부터 계속해서 T[key + 1] 해주는것 처럼, 다음 슬롯을 살펴보면서 값을 찾는다. 만약 빈 슬롯이 나오면 찾고자 하는 값이 없는것을 의미한다.
Linear Probing의 단점은 cluster들이 생긴다는 것이다. cluster는 키들이 특정 테이블 인덱스 주변에 뭉쳐지는 현상인데, 이 cluster는 한번 생기면 눈덩이 굴리는 것처럼 점차 커지게 된다. 새로운 값을 삽일 할 때 cluster 위에 삽입할 가능성이 커지고 결국 삽입시에 빈 공간을 탐색하는데 오랜시간이 걸리게 될 것이다.
그리고 Linear Probing는 그냥 값을 삭제하면 문제가 생긴다.
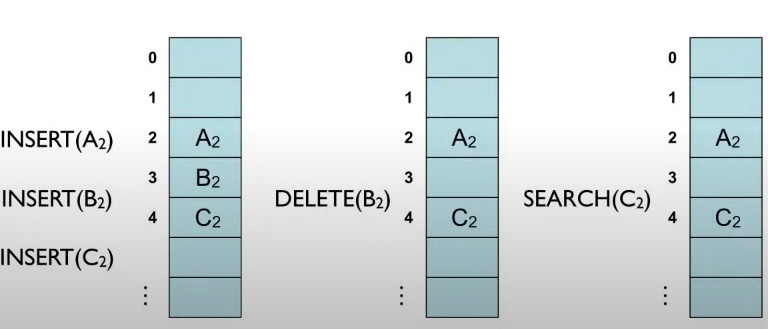
Linear Probing 기법으로 A2, B2, C2를 삽입하고 B2를 삭제하면 두 번째 리스트 처럼 가운데 빈 공간이 생긴다. 이러면 문제가, C2를 찾고자 할 때, C2의 해시값에 해당하는 슬롯에 접근하는데, A2를 보고 찾는 값이 아니기에 다음 배열로 이동하면서 탐색해야한다. 하지만 중간에 빈 슬롯이 있기 때문에 키에 해당하는 값이 없다고 판단하는것이다.
때문에 클러스터의 제일 마지막 원소부터 시작해서 삭제된 빈 공간의 인덱스보다 해시 값이 작은 첫번째 원소를 찾아서 삭제된 빈 공간으로 옮겨주는 작업이 필요하다.
이외에도 Quadratic probing과 Double Hashing 기법이 있는데, 이 둘은 Linear probing과 충돌을 대하는 방식이 비슷하다. 다만 Quadratic probing 기법은 충돌이 일어났을 때 Linear probing이 한 칸 뒤 슬롯에 넣는 반면, 해시값에 특정한 값의 제곱을 더해 매핑한다. 예를 들어 h(2)에서 충돌이 발생하면 첫 번째 충돌 해시값에 + 1^2를 다음 충돌에는 h(2) + 2^2 를 해주는 형식이다.
Double hasing은 해시 함수를 하나 더 둬서 충돌이 발생했을 때 몇 슬롯 뒤에 매핑해줄 지 정하는 기법이다.
바람직한 해시함수
바람직한 해시함수는 반환값이 키의 특정 부분에 의해서만 결정되면 안된다. 현실에서는 학번, 군번 같이 key들이 일정한 패턴을 가지는 경우가 많기 때문에, 특정 부분에 의해서 해시값이 결정된다면 충돌이 많이 발생할 수 밖에 없다.
충돌을 없애는 것은 불가능 할테지만 잘 고안된 해시함수로 충돌을 줄이는 것이 바람직한 해시함수라고 할 수 있다.
'자료구조' 카테고리의 다른 글
| 리스트(List), 배열(Array), 연결 리스트(Linked List) (1) | 2022.11.18 |
|---|---|
| 큐(queue), 덱(dequeue) (0) | 2022.11.11 |
| 스택 (Stack) (0) | 2022.07.19 |

